AudioSpace: Generating Spatial Audio from 360-Degree Video
Abstract
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework AudioSpace, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, AudioSpace features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that AudioSpace achieves state-of-the-art performance across both objective and subjective metrics on Sphere360.
AudioSpace 360° Interactive Video Demo Player
🎧 Please wear headphones and drag the screen to experience the 360-degree audio 🎥.
Motivation
The rapid advancement of virtual reality and immersive technologies has significantly amplified the demand for realistic audio-visual experiences.
However, current video-to-audio methods typically generate non-spatial (mono or stereo) audio, which lacks essential directional information, and rely on limited perspective videos that miss crucial visual context.
As illustrated in Figure 1-a, panoramic videos capture a complete 360-degree view, enabling the simultaneous observation of all sound sources—such as a moving train—that remain invisible in frontal perspectives.
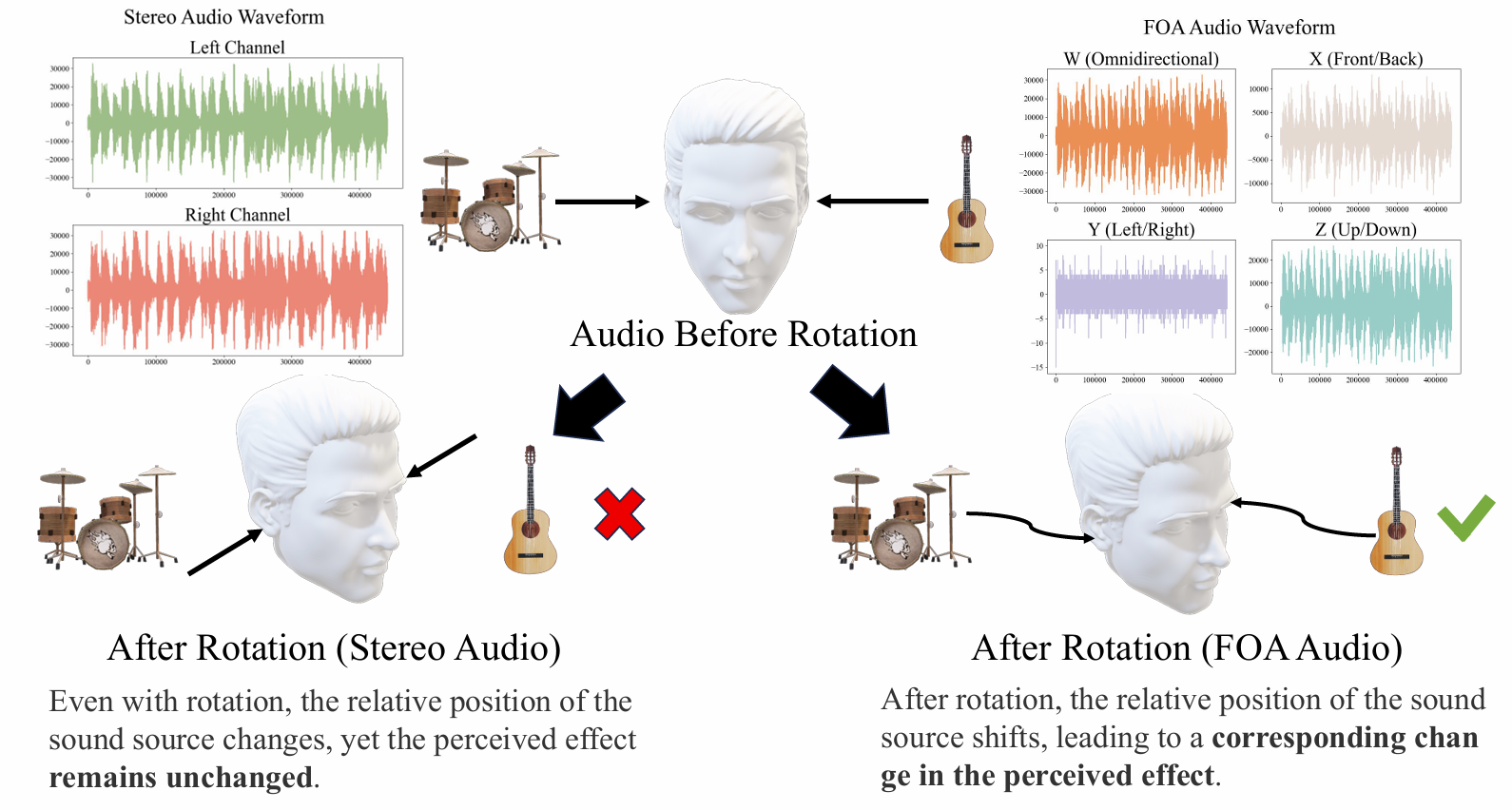
Additionally, Figure 1-b shows that stereo audio fails to maintain sound localization during head rotations, whereas spatial audio in First-order Ambisonics (FOA) retains accurate positioning.
To address these limitations, we introduce 360V2SA, a novel task that generates FOA spatial audio directly from 360-degree videos, leveraging comprehensive visual information to enhance audio realism and immersion.
(a) Comparison of panoramic video and perspective video.
(b) Comparison of stereo audio and FOA audio under head rotation.
Figure 1. (a) shows the scene of a moving train that appears and gradually disappears in a panoramic view without being visible in the frontal perspective. (b) compares the audio localization before and after head rotation, illustrating how stereo audio fails to maintain sound localization while spatial audio (in FOA format) retains accurate positioning.
Architecture
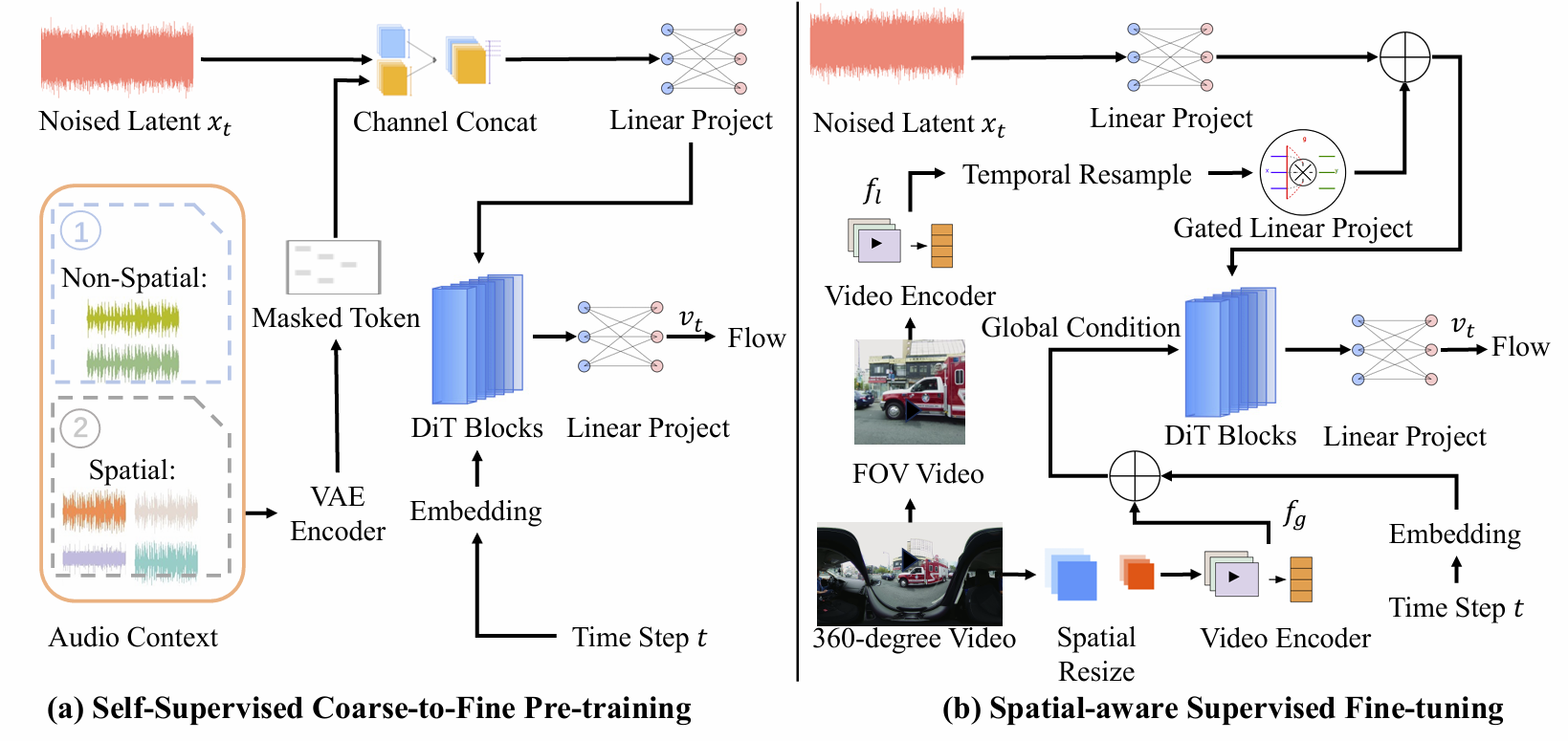
As illustrated in Figure 2 , AudioSpace consists of two main stages: (1) we employ a coarse-to-fine self-supervised flow matching pre-training (Figure 2a) to alleviate the issue of data scarcity using both unlabeled spatial and non-spatial audio.
(2) In the fine-tuning stage (Figure 2b), we perform spatial-aware supervised fine-tuning by utilizing a dual-branch video representation combined with a flow matching objective.
Figure 2. A high-level overview of AudioSpace. The model leverages stereo and FOA audios for self-supervised pre-training using token masking. AudioSpace efficiently trains for conditional generation during fine-tuning, supported by robust panoramic video representation. DiT denotes Diffusion Transformer.
Comparisons with Baselines
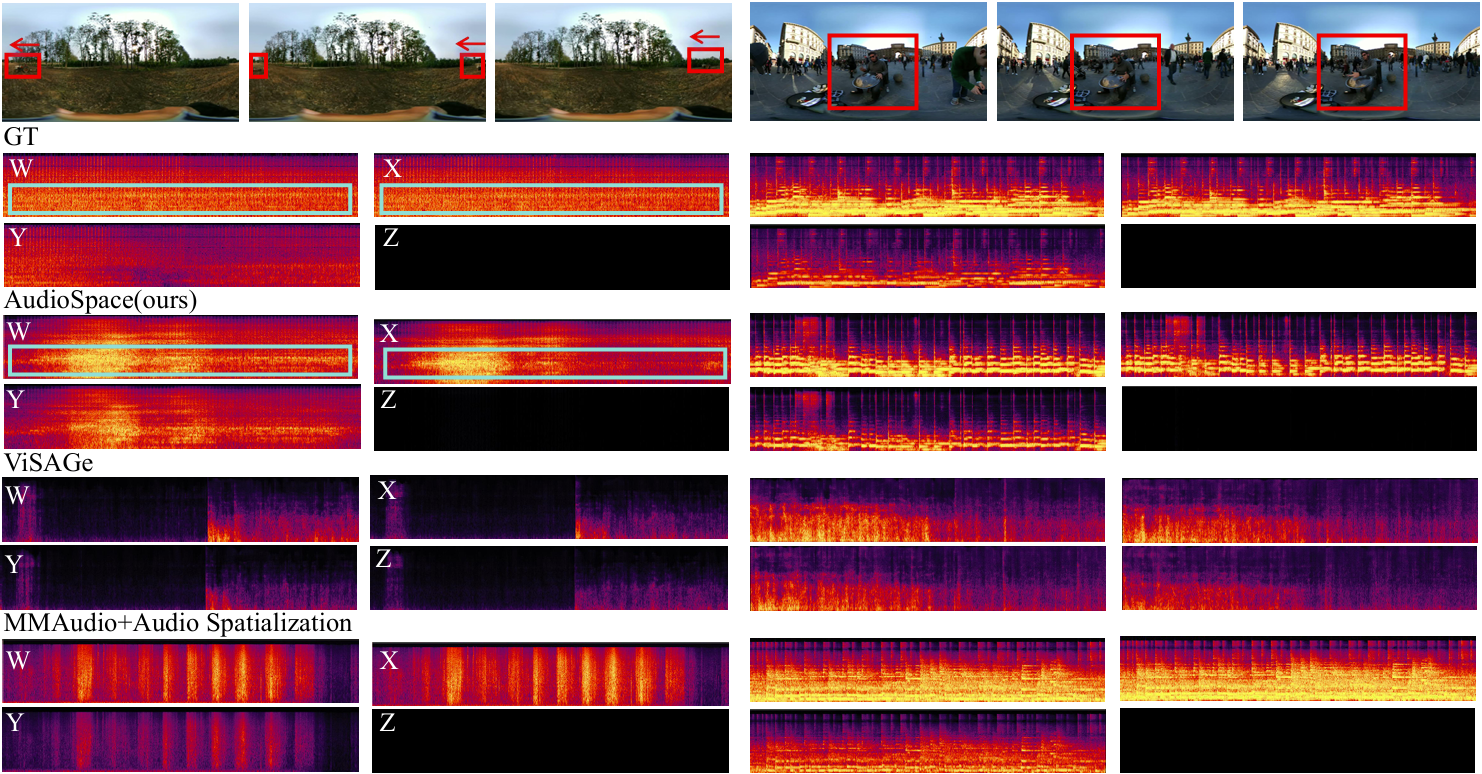
The following presents a comparison between the ground truth (GT), the results generated by AudioSpace, and two baseline methods: a cascaded system that integrates the state-of-the-art video-to-audio generation model MMAudio (a FoV Video + Text to Monophonic Audio model) along with an audio spatialization component (AS, which uses GT angle rendering for spatialization), and ViSAGe, a recent model designed for generating spatial audio from perspective video inputs, producing 5-second audio segments. Details of the spatialization component can be found in the appendix. Each video provides a different perspective on the 360-degree audio experience. The video ID format is "youtube id _ start time(s)", with each video segment lasting 10 seconds. FOA audio from these videos is decoded into binaural audio using Omnitone. Once again, please make sure to wear headphones 🎧 and drag the screen to fully experience the 360-degree audio 🎥.
Scene Transition Cases
We used single-scene videos, paired them into groups, and spliced 5-second segments into 10-second clips with abrupt transitions to evaluate whether the model can better handle sudden changes in the scene.
Ablation Study
Ablation Study
This section presents the comparison of generation results for the models listed in Tables 3 and 4 of the paper.
Quantitative and Qualitative Results
Model
Dataset
FD↓
KL↓
Δabsθ↓
Δabsφ↓
ΔAngular↓
MOS-SQ↑
MOS-AF↑
GT
YT360-Test
/
/
/
/
/
85.38±0.95
87.85±1.21
Diff-Foley + AS
YT360-Test
361.65
2.22
/
/
/
67.21±0.95
70.34±1.76
MMAudio + AS
YT360-Test
190.40
1.71
/
/
/
73.25±1.05
76.77±1.23
ViSAGe (FOV)
YT360-Test
199.09
1.86
2.21
0.88
1.99
71.82±1.98
72.17±1.47
ViSAGe (360)
YT360-Test
225.52
1.95
2.18
0.86
1.98
72.45±1.64
72.96±1.39
AudioSpace
YT360-Test
92.57
1.64
1.27
0.53
1.27
80.37±0.91
83.49±1.01
GT
Sphere360-Bench
/
/
/
/
/
88.41±0.79
90.12±1.08
Diff-Foley + AS
Sphere360-Bench
331.05
3.56
/
/
/
69.87±0.84
71.12±1.36
MMAudio + AS
Sphere360-Bench
271.15
2.39
/
/
/
75.34±0.99
77.56±1.22
ViSAGe (FOV)
Sphere360-Bench
210.87
2.90
1.51
0.71
1.49
73.45±1.42
74.89±1.71
ViSAGe (360)
Sphere360-Bench
219.66
2.96
1.52
0.74
1.51
74.12±1.18
75.34±1.03
AudioSpace
Sphere360-Bench
88.30
1.58
1.36
0.52
1.28
84.67±1.06
87.23±0.98
Table 1. Performance comparison between AudioSpace and the baselines on the Sphere360-Bench test set and YT360 test set. We use objective metrics computing FD, KL divergence, Δabsθ, Δabsφ, and ΔAngular between estimated DoA and ground truth, as well as subjective metrics including MOS for spatial audio quality (MOS-SQ) and video-audio alignment faithfulness (MOS-AF). We report the mean and standard deviation for MOS-SQ and MOS-AF. +AS denotes adding an audio spatialization component. For metrics with a downward arrow (↓), lower values represent better performance, while for metrics with an upward arrow (↑), higher values indicate better quality.
Model
FD↓
KL↓
Δabsθ↓
Δabsφ↓
ΔAngular↓
coarse-to-fine
88.30
1.58
1.36
0.52
1.28
w/ fine
97.57
1.82
1.36
0.57
1.28
w/ coarse
97.26
1.78
1.36
0.66
1.30
w/o PT
104.57
1.83
1.39
0.58
1.32
Table 2. Effect of Self-supervised Pre-training on various metrics: FD, KL, Δabsθ, Δabsφ, and ΔAngular. The arrows indicate that lower values are preferred for these metrics.
Model
FD↓
KL↓
Δabsθ↓
Δabsφ↓
ΔAngular↓
ERP+FOV
88.30
1.58
1.36
0.52
1.28
EAC+FOV
89.89
1.66
1.33
0.55
1.29
w/ FOV only
88.80
1.87
1.41
0.59
1.33
w/ EAC only
93.37
1.84
1.37
0.57
1.30
w/ ERP only
97.83
1.87
1.35
0.59
1.28
Table 3. Effect of the Dual-branch Design on various metrics: FD, KL, Δabsθ, Δabsφ, and ΔAngular. The arrows indicate that lower values are preferred for these metrics.
Figure 3. Qualitative Comparison. The first case on the left shows an agricultural machine moving behind, with the rectangular annotation indicating a decreasing trend in sound intensity in the GT audio. The second case on the right features a person playing a musical instrument. Since ViSAGe only generates 5-second audio, we concatenate the segments.
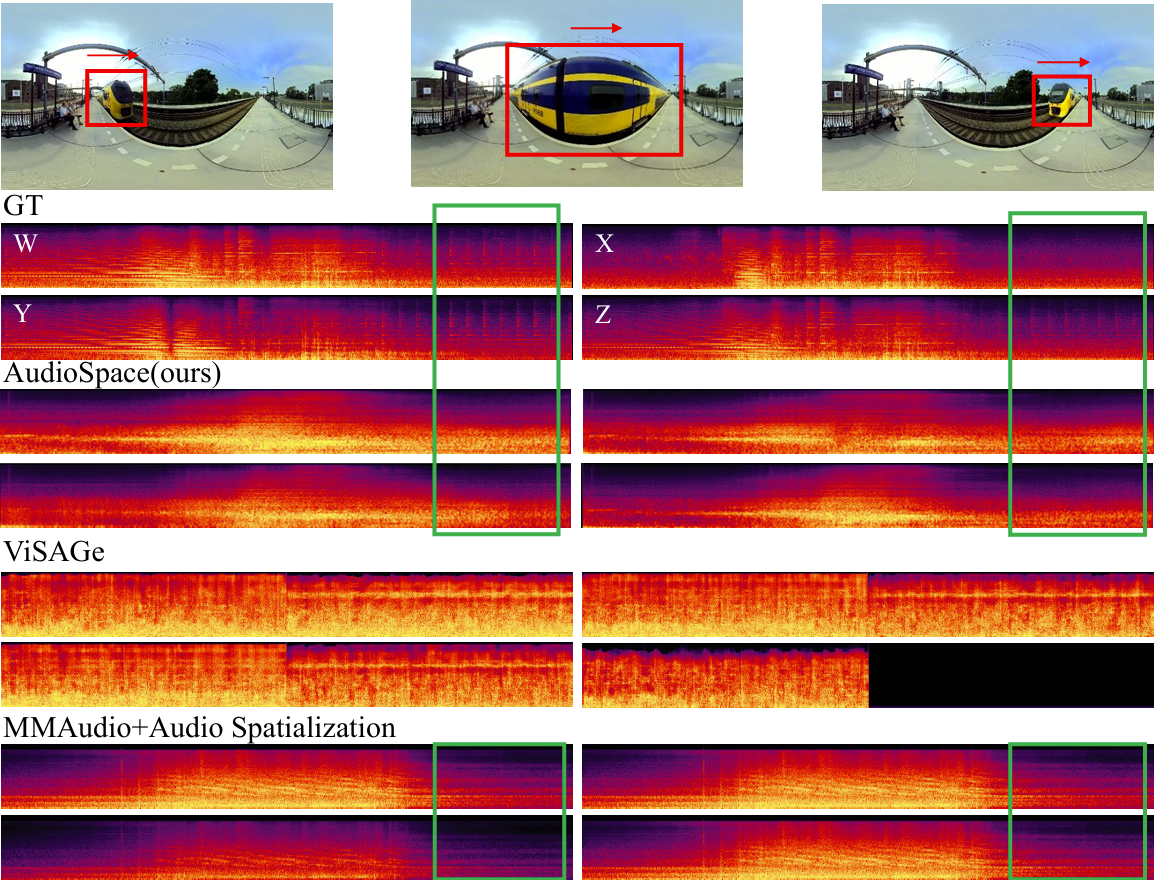
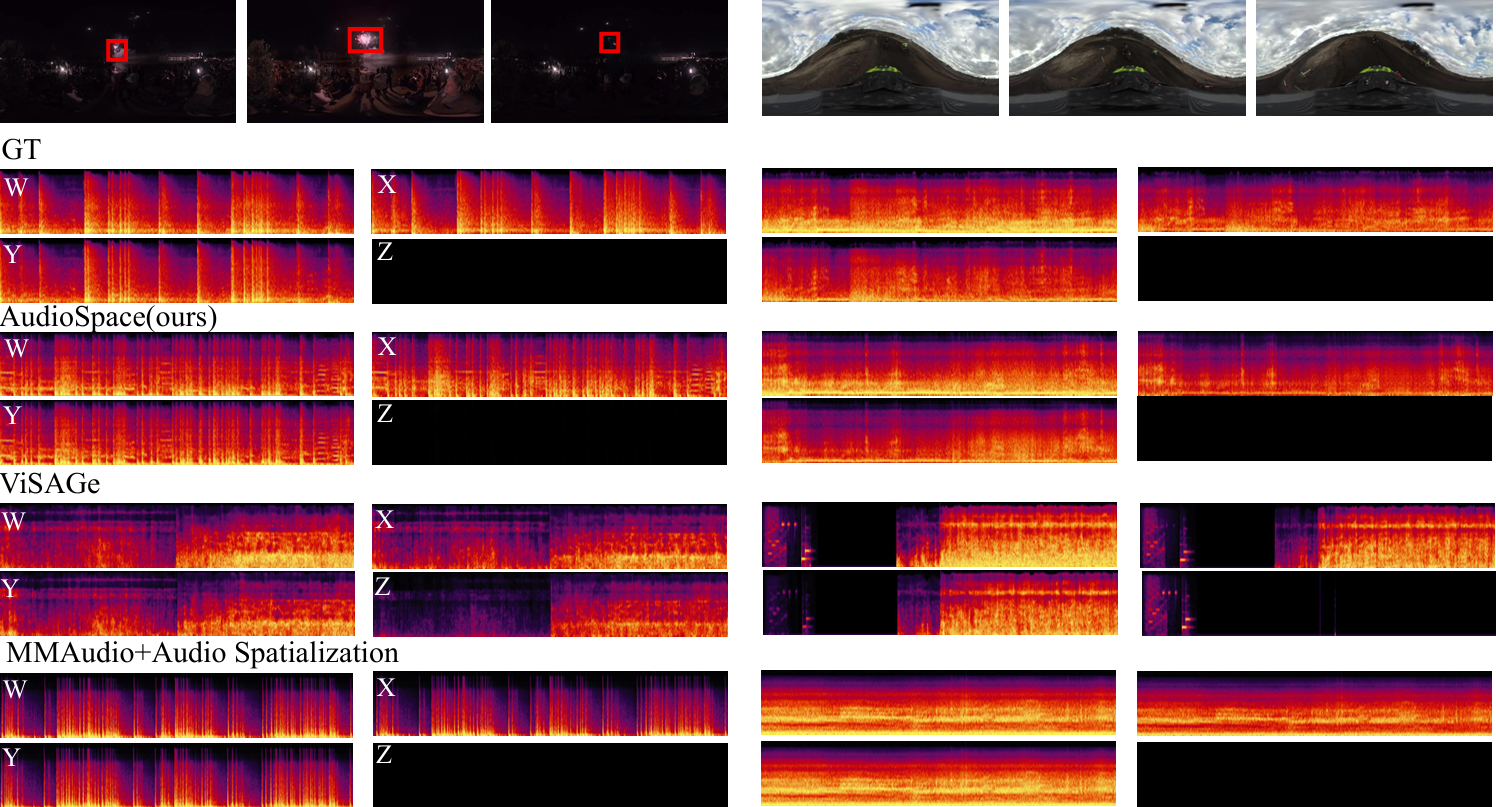
Figure 4. Additional Quantitative Results. This case shows a train passing by. The rectangular annotation indicates that the audio generated by our model continues to capture the sound of the train leaving the frontal perspective, even after it has passed, while the audio generated by other models almost entirely fades once the train moves out of the frontal view.
Figure 5. Additional Quantitative Results. The case on the left shows a continuous display of fireworks rising into the sky and exploding. The case on the right depicts several motorcycles chasing each other on a dirt road, with intense wind and engine sounds.
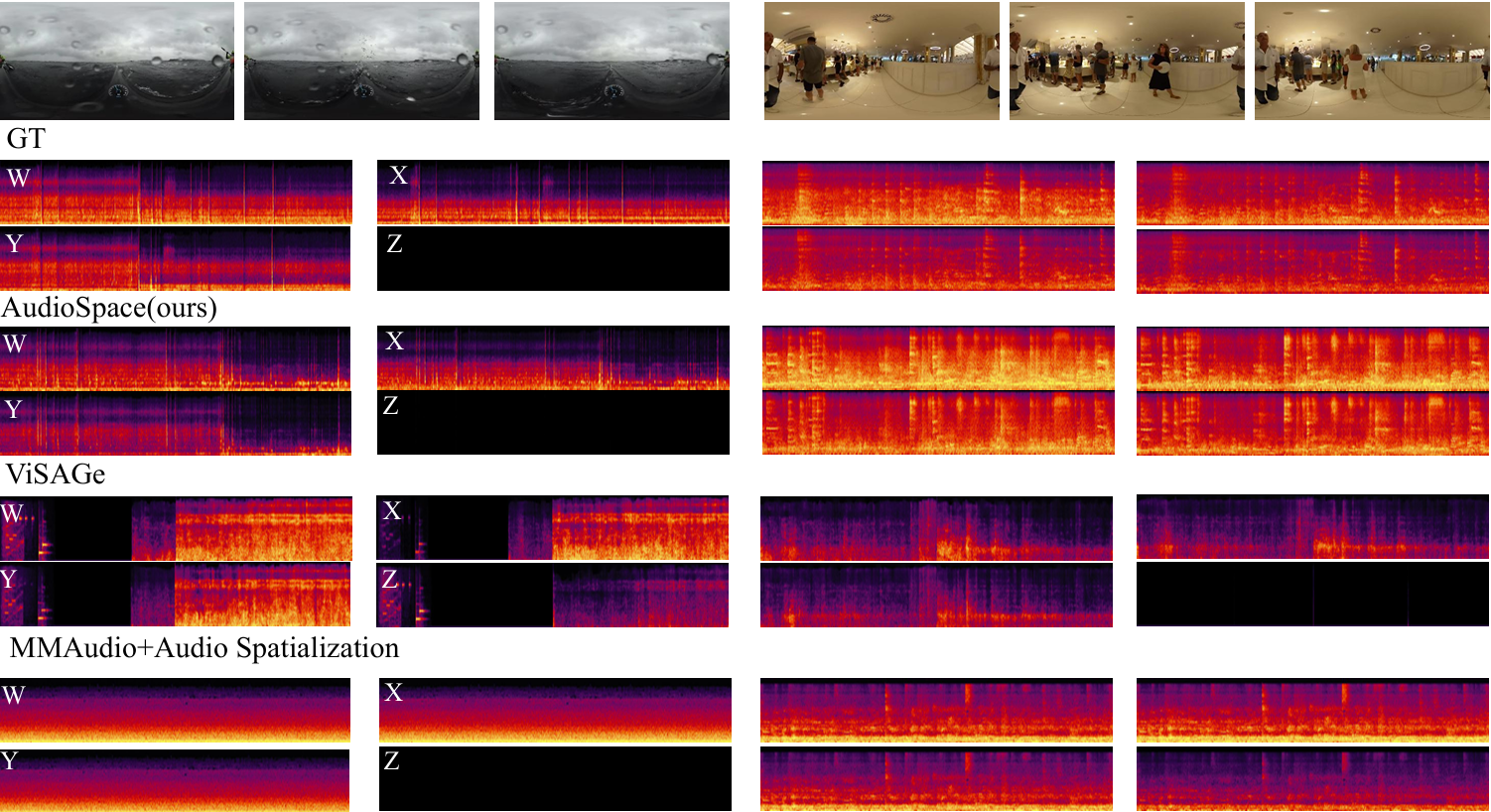
Figure 6. Additional Quantitative Results. The case on the left shows a camera mounted on a boat navigating through the waves, with the bow plunging into the water and splashing onto the screen. The case on the right shows the viewpoint moving through a noisy crowd in an indoor environment.
Code and Dataset
The code can be found
here.
The dataset is available
here.
Acknowledgments
We would like to thank Omnitone for the 360° Interactive Video Demo Player.